요즘 인턴하는 회사에서 신사업 외주 맡긴 건을 맡아서 성능 분석하고 있다. 합의하의 시나리오를 짜서 외주 모델을 검증하고 있는데 간만에 본 SPO님한테 한 요청이왔다. 나는 항상 분석을 해서 주마다 해당 개발팀장님에게 넘겨주었는데, 팀장님이 내가 준 자료를 그대로 들고가서 회의에 참가했다고 한다. 헌데 비지니스 그룹에선 이해하기 힘들다는 이야기였다. 그래서 SPO님이 먼저 해당 신사업 진행을 결정 할 수 있는 숫자를 요청했다. 그때 머신러닝 시간때 배운 평가 지표가 생각나서 작성해서 드렸다. 작성하면서, 한 번 기록해놓으면 나중에 찾아볼 때 좋을 것 같아 이렇게 글을 적는다.
| Confusion Matrix | Actual | ||
| 1 | 0 | ||
| Expected | 1 | True Positive | False Positive |
| 0 | False Negative | True Negative | |
먼저, 위와 같은 Confusion Matrix를 구해놔야 평가지표를 쉽게 구할 수 있다.
- True Positive : 모델이 예측한 값은 true인 데, 실제 데이터도 true인 경우 (예측 O)
- False Positive : 모델이 예측한 값은 true인 데, 실제 데이터는 false인 경우
- False Negative : 모델이 예측한 값은 false인 데, 실제 데이터는 true인 경우
- True Negative : 모델이 예측한 값은 false인 데, 실제 데이터는 false인 경우 (예측 O)

: 모델이 전체 문제 중에서 정답을 맞춘 비율이다. 즉, 전체 예측한 것 들 중 정답을 맞힌 true의 비율이다. 실제 데이터에 negative가 많아서 positive를 맞췄는지 여부와는 상관없이 정확도가 올라 갈 가능성이 존재한다. 이를 Accuracy Paradox(정확도 역설)라고 한다. 이때 희박한 가능성으로 발생할 상황에 대해서는 recall 값을 보고 판단하면 된다.
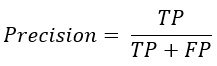
정밀도 = Positive Predictive Value
: 예측한 것 중에 정답의 비율은? 모델이 positive라고 예측한 것들 중에서 실제로 정답이 positive인 비율이다. recall과 반대 개념으로 precision을 이용할 수 있다. 하지만 둘만으로 알고리즘 성능 표현이 부족해서 생긴 것이 F1 score이다.

재현율 = Sensitivity = True Positive rate
: 찾아야 할 것중에 실제로 찾은 비율은? 실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율이다. Accuracy는 낮지만 recall 값만 높은 경우는 precision 값을 통해 알고리즘에 결함이 있음을 판단해야한다.

Precision과 Recall의 조화 평균
: 산술평균을 쓰지 않고, 조화 평균을 쓰는 이유는 recall과 precision 둘 중 하나가 0에 가깝게 낮을 때 지표에 그것이 잘 반영되도록 하기 위함이다.
'QA' 카테고리의 다른 글
| API testing guidelines (0) | 2023.04.05 |
|---|---|
| Smoke Testing vs Regression Testing (0) | 2023.04.03 |
| Production Environments (0) | 2023.03.28 |
| JMeter를 알아보자! (0) | 2023.02.07 |
| [스압주의] QA 톺아보기 (+WEST program) (0) | 2022.12.31 |